SQL provides a dedicated structure to speed up the retrieval of rows from a table called index.
This sorted data structure is called a B-tree (balanced tree). B-tree structure enables us to find the queried rows faster to using the sorted key value(s). Table data can be sorted physically in only one direction for this reason we can define only one clustered index per table. The following image illustrates a logical structure of the clustered index.
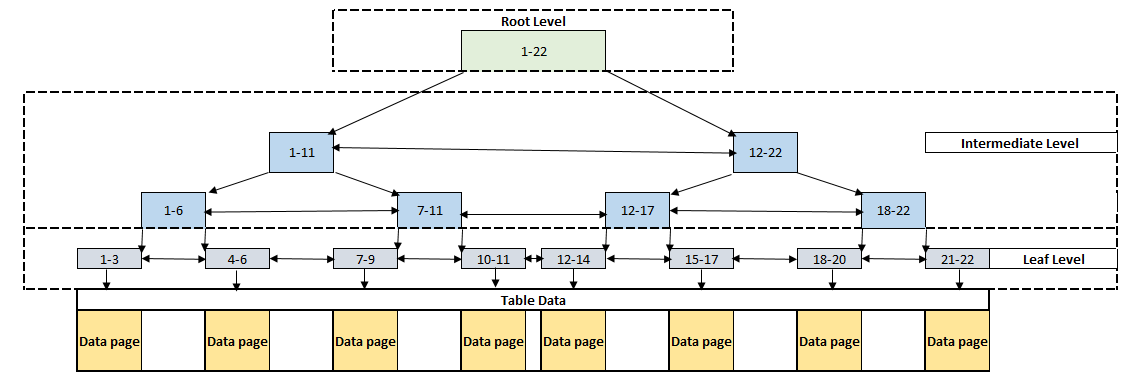
The root and intermediate levels contain the index key values and page pointers. The page pointers point to the previous and subsequent index pages of their own. These two levels don’t store any row data. At the same time, index pages hold information about the ahead and behind index page numbers.B-tree structure based-on three different levels:
- Root level: The top level of the B-tree is called as root level. The root level is the starting point of the data searching
- Intermediate level: This level provides a connection between root and leaf levels. SQL Server does not create an intermediate level when the amount of data rows are too small
- Leaf Level: This level is the lowest level of the clustered index and all records are stored
In this execution plan, the seek predicates indicate that the storage engine uses the B-tree structure and finds the leaf level that stores the data rows. For this query, the uniqueness of the clustered index is very important because this constraint guarantees that only one row will return from the query. This data searching concept is called singleton seek.
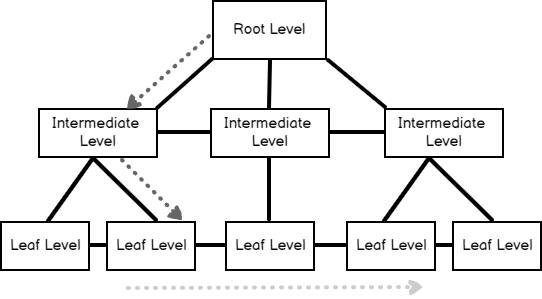
The following image illustrates how the multiple singleton seek process works:
SQL Server Clustered Index and Primary Key
when we create a primary key SQL Server creates a unique clustered index. However, we can create a primary key without a clustered index because the only mandatory requirement is uniqueness for the primary key. So the main differences between the primary key and clustered index are:
- A primary key is a logical structure and it provides the uniqueness for a table
- A clustered index is a physical structure and it provides the physical order of the records on the storage
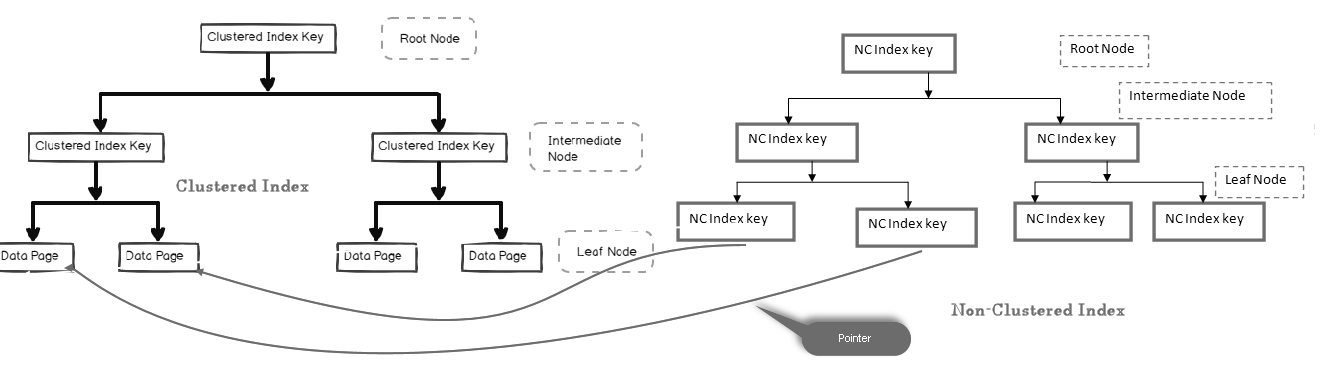
We can have multiple non-clustered indexes upto 999 in SQL tables because it is a logical index and does not sort data physically as compared to the clustered index.
Some Important point of Non Clustered Index:
Index added to the table will negatively impact data modification performance on that table. This is due to the fact that, when you modify a key column in the underlying table, the Non-clustered indexes should be adjusted appropriately as well.
When designing a Non-clustered index, you should consider the type of the workload performed on your database or table:
create a minimum of narrow indexes, with a minimum number of columns participating in the index key, on the heavily updated table.
A table that has a large number of rows with a low data modification requirement can heavily benefit from more Non-clustered indexes with composite index keys, that contain more than one column in the index key, that cover all columns in the query to improve the data retrieval performance.
it is highly recommended to avoid adding too many key or non-key columns to the Non-clustered index that are not required by the queries,Adding too many columns to the index will result with fewer number of rows that can be fit in each data page, increasing the I/O overhead and reducing the caching efficiency.
Syntax:
create nonclustered index nonclusterdemo on employee (dept)
Non Clustered Index Implementation: When you create a UNIQUE constraint, a unique Non-clustered index will be created automatically to enforce that constraint.
To be able to create a Non-clustered index, you should be a member of the sysadmin fixed server role or the db_ddladmin and db_owner fixed database roles.
CREATE TABLE NonClusteredDemo (ID INT IDENTITY (1,1) NOT NULL, StudentName NVARCHAR(50) NULL,
STDBirthDate DATETIME NULL,STDPhone VARCHAR(20) NULL,STDAddress NVARCHAR(MAX) NULL)
CREATE NONCLUSTERED INDEX IX_NonClusteredIndexDemo_StudentName ON NonClusteredDemo(StudentName)WITH (ONLINE = ON , FILLFACTOR=90)
The ONLINE option allows concurrent users access to the underlying table or the Clustered index data during the Non-clustered index creation process.
FILLFACTOR option is used to set the percentage of free space that will be left in the leaf level nodes of the Non-clustered index during the index creation, in order to minimize the page split and fragmentation performance issues.
Non Clustered Index with Include Column:
Different Scenario to create Index and to avoid creating index
Example, How index is effective